


There is a pattern that, as investor in the project economy, I’ve seen many times, and it goes something like this: a genuinely painful (e.g. construction) industry problem gets identified (correctly), a wave of startups raises venture capital to solve it with the latest technology paradigm (enthusiastically), and then the structural realities of the (e.g. construction) industry slowly grind away at the initial thesis until what remains is a modest productivity tool.
I am being vague, so you’re probably wondering: what are the latest examples? It has to do with AI. More specifically, AI procurement agents.
The pitch is compelling on the surface. Construction materials represent roughly 40-55% of hard project costs. Around 85% of construction projects globally have experienced cost overruns over the past seventy years, with an average overrun of 28 percent. Approximately 88% of construction firms reported project delays from supply chain disruptions in recent surveys. Rework alone, often triggered by incorrect material orders or specification errors, costs 5 to 15% of the total project value.
Enter: AI. The promise: use AI agents to automate the process of sourcing, ordering, tracking, and paying for construction materials. Replace the spreadsheets, the phone calls, the emailed PDFs, the manual three-way invoice matching, and the human error that plagues every step of the procurement cycle.
I want to be clear about something upfront: these tools are genuinely useful. They solve real problems for real customers. The efficiency gains are not (entirely) fabricated. But usefulness and defensibility are entirely different questions, and this article is primarily concerned with those two topics.
The uncomfortable thesis I want to develop here is that ultimately, these companies are stuck competing for a thin slice of the value chain while becoming increasingly commoditized.
What AI procurement actually are (and aren’t)

Construction procurement is essentially a specification-to-pay pipeline: it starts with specification and scope definition, moves through tendering and buyout, then ordering, delivery and receiving, invoicing and reconciliation, and finally payment and compliance.
Therefore, different AI agents can target different stages: some might address takeoff and quantity estimation, others handle specification parsing and product matching, a cluster of companies intervene in sourcing, RFQ generation, and supplier selection, a growing number automate invoice processing, reconciliation, and spend analytics. You get the gist.
Ultimately, the dominant technical architecture of AI procurement agents is what you might call an orchestration layer: the product sits on top of other solutions to run them better, it does not replace them.
The critical pattern is that these tools overwhelmingly augment rather than replace existing procurement workflows. In the best implementations, automation handles the bulk of routine accounts payable and receivable, but humans manage exceptions. AI answers document queries in seconds, but humans make final decisions: the "human-in-the-loop" principle is not a marketing nicety but, rather, a design necessity in an industry where a single specification error can cascade into significant rework costs.
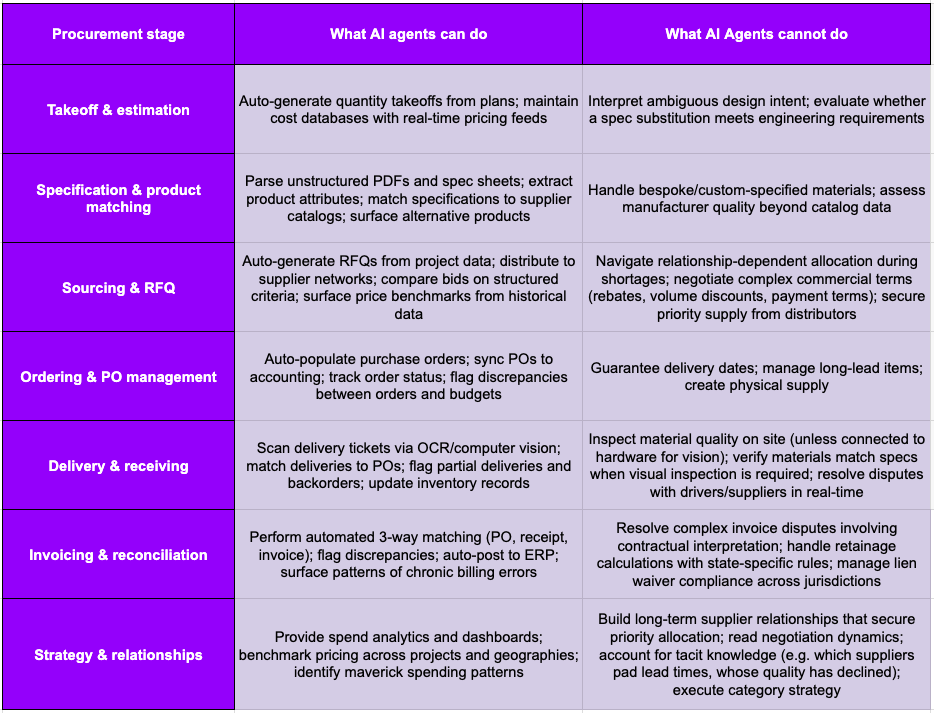
What this table reveals is a fundamental asymmetry: AI agents excel at structured, repetitive, data-heavy tasks like parsing documents, matching records, flagging discrepancies, generating reports, but they struggle with everything that requires physical-world judgment, relationship navigation, contextual interpretation, and the kind of tacit knowledge that experienced procurement professionals carry in their heads. And it is precisely the latter category, the hard problems, that drives most of the cost overruns and schedule delays in construction.
Usefulness is not the same as defensibility

Now let us turn to the question that matters most from an investment perspective: can AI procurement agents build defensible businesses?
I'll be direct: from my vantage point, the underlying technology deployed across the construction procurement agent space is standardized, the models are commodity, and whatever differentiation exists is operational rather than technical. Consider the core technical capabilities that (most of) these products are built on: matching unstructured material descriptions across different supplier naming conventions is fundamentally a named entity recognition and fuzzy matching problem that modern LLMs handle competently out of the box. Extracting structured data from construction product PDFs and spec sheets is a well-established document extraction pipeline that general-purpose multimodal models handle with increasing facility. Running retrieval-augmented generation over project documents is literally one of the most common LLM application patterns in existence. Applying time-series forecasting and classification to construction financial data uses well-established ML approaches where the differentiator is training data volume. None of these capabilities, taken individually or together, represent in my opinion a proprietary technical breakthrough: they are simply applications of commodity AI to domain-specific data.
The defensibility, to whatever extent it exists, lies in accumulated data assets and operational execution, not in the AI models themselves.
Meanwhile, the incumbents are moving fast. ERP vendors and project management platforms have shipped or announced agentic AI capabilities within their existing products, often included at no extra cost in existing subscriptions. These incumbents sit on vastly more data and have established distribution into tens of thousands of contractor accounts.
The broader AI ecosystem has already shown us what happens when the agent layer commoditizes. We have seen billion-dollar-plus valuations evaporate in adjacent verticals when the underlying foundation model providers launched their own consumer products. Construction procurement AI involves more complex multi-party workflows than, say, content generation, which provides somewhat more room for differentiation. But the core risk applies directly.
The data defensibility claims made across this category, in my opinion, fare poorly against established frameworks for evaluating data moats.
Start with product databases built by scraping manufacturer websites. This is a common approach in the space: crawl thousands of sites, extract product attributes from PDFs, build a structured catalog. The problem is that the source data is publicly available, posted by manufacturers specifically for customer access. Any competitor with engineering resources could replicate the effort in months (weeks?) using the same tools. Hence, scraping publicly available data does not create a moat, it only creates a head start that erodes quickly.
Transaction data accumulated through procurement platforms has more genuine value because it can reveal actual prices paid (not list prices), supplier delivery performance, and fill rates. But vendors typically receive only a license to use aggregated and anonymized data: this means the data asset depends on continued customer relationships, and churn destroys it. More fundamentally, construction procurement data fails the criteria that distinguish gold-standard data moats. The most defensible data businesses in enterprise software share common characteristics: exclusive data feeds that cannot be obtained elsewhere, proprietary taxonomies or indices that became industry standards, communication network effects that create lock-in independent of the data itself, and regulatory requirements that mandate use of their specific data. I don't see any of these attributes here.
In fact, data moats tend to work when data is generated exclusively through platform usage, when more data meaningfully improves the product with compounding returns, when transaction frequency is high, when data has a long shelf life, and when network effects compound across users. Construction procurement fails on most of these dimensions: underlying data is often publicly available and anyway not due to product usage, diminishing returns set in quickly after moderate transaction volume, pricing data decays rapidly in volatile markets, and hyperlocal market structures prevent national network effects from compounding.
Another point is on switching costs.
AI procurement agents are typically implemented in a matter of days/weeks (meaning: integration pain is low). This compares to the multiple months (in case of the largest customers) required for construction ERPs implementation, which touch financials, project management, HR, payroll, and compliance. Contractors keep their ERP for a decade or more and consider switching a once-in-a-generation event, due to both direct and indirect costs (e.g. data migration, business disruption, etc.). AI procurement agents involve switching costs that are an order of magnitude (or less) lower.
One potential switching cost is the behavioral one, meaning that once adopted, the reluctance to retrain on a different interface creates larger switching friction relative to the actual technical lock-in. This is a real advantage for first-movers, but it is fragile: it depends on sustained user satisfaction rather than structural barriers, and it protects incumbents (including non-AI incumbents) as much as it protects innovators.
The bottom line on defensibility: there are layers of potential competitive advantage (proprietary supplier data, workflow specialization, integration depth, network effects), but each layer is individually moderate and collectively still insufficient to prevent commoditization pressure from both foundation model improvements and incumbent platform absorption. The problem for construction procurement agents is that even the layered version of their moat is thinner than it looks.
Whoever owns the truth holds the power

This is, in my opinion, the most important structural argument against standalone AI procurement agents as durable, independent businesses.
The argument, in its simplest form, is this: AI agents are intelligence layers. They sit on top of systems of record. Systems of record are where the truth lives, and in enterprise software, whoever owns the truth holds the structural power.
Now, let me expand on this. First, let's answer the question: what are systems of record, and why do they matter?
A system of record is the authoritative source for specific business data, the one place where a given piece of information is considered canonical. In construction procurement, the system of record is typically the construction accounting or ERP system where commitments, actuals, accounts payable, and the general ledger are maintained. It might also include project-management platforms that serve as the operational front office for project teams while synchronizing with the accounting system of record.
Systems of record are not just databases that happen to have user interfaces. They are transactional processing engines with embedded computational logic, ACID guarantees (atomicity, consistency, isolation, durability), audit-grade controls, and regulatory compliance mechanisms. A mid-size company's ERP typically contains 50,000 to 100,000-plus database tables. Major ERP systems comprise hundreds of millions of lines of code implementing tax calculations, depreciation methods, revenue recognition rules, cost allocation algorithms, and currency conversion with hedge accounting. An AI agent calling APIs receives data outputs, not the engine that produces them. Remove the ERP, and the agent has no computational backbone for future transactions. This matters in construction more than in almost any other industry, since construction ERPs handle job costing with multi-level cost code structures tracking costs across labor, material, subcontract, equipment, and overhead against budgets.
Construction is, in fact, uniquely resistant to ERP displacement for five reinforcing reasons: audit intensity, regulatory density (no other industry combines prevailing wage, certified payroll, bonding, lien law, and DBE tracking in a single compliance environment), accounting uniqueness (percentage-of-completion is its own world), format rigidity, and technology adoption culture (the average contractor operates on a 7-to-10-year ERP upgrade cycle and spends only 1 to 2 percent of revenue on technology). These five factors compound each other: the audit and regulatory requirements demand a stable, deterministic system, the accounting uniqueness means generic alternatives cannot substitute, the format rigidity means the system must produce exact outputs, and the adoption culture means whatever is in place stays in place for a very long time.
Beyond the functions themselves, three categories of ERP data are particularly resistant to being copied or replicated by an external agent. First, system-generated audit trails: ERPs create tamper-evident logs where the chain of custody is integral to the data's legal value, and copying an audit trail into another system destroys its provenance since auditors require the trail to be generated by the system of record itself. Second, workflow state: a purchase order in "pending VP approval" status depends on the workflow engine's state machine, role assignments, delegation rules, and escalation timers, none of which transfer via API. Third, continuously generated derived data: depreciation schedules, amortization tables, cost allocations, and real-time reconciliations are algorithms operating on data, not static records that can be extracted and rehoused.
And then there is the transactional layer itself. A single ERP business transaction, posting an invoice for instance, may atomically update 10 to 20 database tables simultaneously: general ledger entries, subledger entries, tax records, cash flow projections, aging buckets, and bank clearing accounts. If any single update fails, all must roll back. This is what ACID guarantees provide, and it is what AI agents structurally lack. An agent making sequential API calls has no transactional boundary spanning multiple systems, no mechanism for atomic rollback, no concurrent user isolation, and no deadlock detection.
And there is a practical governance problem that I think gets overlooked in these discussions. If agents are going to take real actions on behalf of a business (e.g., placing orders, approving invoices, committing spend), then they need constraints. What data can they access? What actions are they authorized to perform? Where do their outputs get recorded, and who is accountable when something goes wrong? These are operational requirements in any environment where money changes hands. And when you think about where those constraints should live, the answer is almost obvious: the system of record. It already has structured data, it already has permission models, it is legible to both humans and machines, and it is, for the most part, kept current. The more autonomous agents become, the more critical this governance layer gets, not less. And the system of record is already built for exactly this purpose!
This is why, for the most part, AI agent companies position themselves as connecting to existing accounting systems and vendor networks. Nobody is trying to replace the ERP. Everyone is trying to sit on top of it. And that positioning is a structural necessity.
Some people argue the opposite case.
The strongest version of the replacement thesis argues that most enterprise software is fundamentally CRUD apps with workflows that LLM-powered agents can replicate, and that AI will make custom software creation so frictionless that packaged enterprise software becomes unnecessary. A more moderate version argues that AI agents will commoditize ERPs by abstracting away their user interface, reducing them to "dumb databases" while the agent layer captures the high-value interaction.
Both, in my opinion, fail on examination. First, the strong claim collapses under technical scrutiny, as previously mentioned: APIs expose a fraction of internal data structures, and ERPs contain not just data but computational logic that produces data. Copying an audit trail into another system destroys its provenance. Workflow state depends on engine internals that do not transfer via API.
Secondly, ERP pricing power derives from factors absent in commodity infrastructure: regulatory lock-in, data gravity (decades of transaction history create irreplaceable context), and process embedding (business processes are encoded into ERP configurations over years of implementation). This is also, incidentally, one of the strongest arguments in favor of ERPs natively absorbing agentic AI features rather than ceding that layer to startups. Frankly, I still struggle to understand why so many people find it difficult to envision ERP vendors building these agents themselves, since they own the infrastructure, they own the data, and they own the permission models and the audit frameworks. The integrations required to make a procurement agent useful are not exotic: you are connecting to email inboxes, cloud storage, and a handful of supplier communication protocols. The technical barrier to building an orchestration layer on top of your own system of record is dramatically lower than the barrier to building one from the outside. The concept of value capture moving away from the system of record layer does not seem to consider that pricing power is also a result of substitute availability. How many SoR are there for a construction company vs how many agents built on top of a SoR can the same company choose from?
If anything, the evidence seems to support my view. Every major enterprise software incumbent has shipped agentic AI capabilities within 12 to 18 months of the AI agents thesis gaining traction in venture circles, which is a historically unprecedented response speed for companies of this size. They are embedding agents directly into their procurement, finance, supply chain, and HR modules, often at no additional cost within existing subscriptions, and positioning AI as a pull mechanism for cloud migration. The marginal cost of adding AI features to an existing platform that already owns the data and the workflow is low. The marginal cost of building a standalone alternative that must first solve distribution, integration, and trust is comparatively higher. This dynamic is already playing out in adjacent verticals: ServiceTitan, having established itself as the system of record for home services contractors, is now building agentic AI directly into its platform rather than leaving that layer open for startups to capture.
The intellectual framework here is worth stating plainly, because I think it captures the structural dynamic precisely. AI capabilities are most likely to be absorbed as features by platforms with existing distribution rather than remaining standalone products. The value of AI is proportional to the context it operates in, and incumbents who own the data have inherently richer context than any startup connecting via API. Switching costs in enterprise software, particularly in construction ERPs where implementations span years and cost millions, create moats that AI startups cannot easily breach. The marginal cost of adding intelligence to an existing platform is trivial compared to the cost of building a new platform around intelligence alone. The Innovator's Dilemma counter-argument is real, but historically it has been overpredicted for ERPs: ERP switching costs are among the highest in all of enterprise software, and construction ERPs specifically serve customers who are, if anything, dramatically underserved by their current tools.
The system of record argument has a not-so-great implication for standalone AI procurement agents: they are structurally positioned in the most vulnerable layer of the enterprise software stack.
If the AI layer is commoditizing, if the systems of record that agents depend on are durable, and if the owners of those systems of record are aggressively building their own agentic capabilities, then standalone procurement agents face a structural squeeze. See my article about commoditizing your complement here.
Optimize the "easy" part

We have now established that the AI layer is commoditizing, that data moats are weaker than claimed, that switching costs are moderately low, and that systems of record hold a durable structural advantage. But there is an even more fundamental issue that I think gets insufficiently discussed: AI procurement agents overwhelmingly address administrative and clerical tasks (the easy problems), while the problems that actually cause project delays and cost overruns remain fundamentally resistant to AI automation.
That's not to say these problems are not worth solving: they are! Digitizing RFQs, auto-populating purchase orders, comparing catalog prices, tracking order status, performing three-way invoice matching, generating spend analytics. They represent genuine inefficiency, and AI can compress them dramatically.
But the hard problems are physics-constrained and relationship-dependent. When critical electrical equipment has lead times stretching into the years, driven by grid modernization demand, data center construction booms, and limited domestic manufacturing of key components, no AI agent can create supply that does not exist. When major mechanical and electrical systems routinely show lead times of 40 to 60-plus weeks, the bottleneck is manufacturing capacity and global supply chain concentration, not information friction. An AI agent can alert you to a shortage marginally faster, perhaps search for alternative suppliers within a known universe, and track order status digitally. But it cannot increase manufacturing capacity, secure priority allocation (which is relationship-dependent), guarantee delivery dates the manufacturer cannot provide, or evaluate whether an alternative product meets site-specific engineering requirements.
The relationship dimension is perhaps the most underappreciated limitation. During shortages, distributors allocate scarce materials to their best customers first, a decision based on years of mutual trust, reciprocity, and personal relationship. A majority of specialty contractors still rely primarily on phone calls and personal networks for procurement. Contractors who maintain loyalty to a supplier during slow periods get priority during busy periods, a long-term relationship calculus that is fundamentally human. Knowing that a particular distributor always pads lead time, or that a supplier's quality has declined, or reading hesitation in a sales rep's voice: these are forms of tacit knowledge that exist nowhere in databases and cannot be automated.
There is a structural dimension that further constrains the value AI agents can capture. All the procurement that is engineered-to-order (e.g. structural steel fabrications, custom switchgear, specialty HVAC systems, curtain walls, transformers, etc) often represents the majority of total material cost and causes the vast majority of schedule delays. These items require iterative engineering collaboration, shop drawing review, code compliance verification, and physical-world judgment: the hallucination risk in technical specification contexts is not theoretical but potentially catastrophic. This, in turn, creates an inverse relationship between addressable capability and economic importance. AI procurement tools are most effective for items that are least critical to project outcomes, while the high-value, high-risk items that drive schedule delays and cost overruns are precisely where AI adds the least value.
Last, this operational limitation maps directly onto a revenue problem. If you are a procurement agent selling SaaS subscriptions, you are most likely competing for the notoriously small IT budget in construction, which often accounts for a mere 1 to 3 percent of total project costs. This is the same budget that every other construction technology SaaS vendor is fighting over. SaaS capture is limited by willingness-to-pay relative to measurable savings, and the ceiling is often closer to a fraction of avoided labor plus error reduction, rather than a percentage of total materials spend, and transaction fee models must remain low because suppliers resist "taxes" without incremental demand generation.
The better path: delivering outcomes, not efficiency

At Foundamental, we have written extensively about outcome-as-a-service models in previous content (see here, here, here, and here), and the argument applies with particular force to procurement. The companies that will capture disproportionate value are (in my view) the ones delivering actual procurement outcomes: guaranteed delivery, verified quality, committed pricing.
The logic maps directly onto how construction companies actually buy: the entire industry is built on subcontracting and outsourcing. Very few general contractors self-perform every task: they orchestrate networks of specialists who are each paid for a specific outcome. This deeply ingrained behavior means the market is already primed to buy outcomes. The budget is already in the P&L. You are not creating a new line item or competing for a discretionary IT budget. You are replacing an existing supplier or service provider by doing something better through technology.
A procurement agent selling SaaS competes for the tiny IT budget. An outcome-oriented procurement company competes for the much larger budgets allocated to materials and subcontracted services, which constitute the vast majority of project expenses. The addressable market shifts from single-digit billions in procurement software to hundreds of billions in annual materials spend.
Mind you that "delivering outcomes" in procurement needs one important qualifier, because there is a tempting middle path I want to rule out explicitly: what I call the "AI-enabled marketplace". I have seen a growing number of these: you describe what you need in a chat box, or upload a drawing and a few photos, the system parses it and matches you with suppliers, and the company clips a take rate on the resulting transaction. It feels like an outcome business because there is a transaction at the end of it, but it really isn't. It is a discovery layer wearing an "outcome's clothing", in figurative terms.
The problem is structural, and it is the same one this article keeps returning to: where does the durable value sit? In a pure marketplace (like an hypothetical AI-led one described above), the value is almost entirely front-loaded into the matching event. Once a buyer and a supplier have been introduced and have transacted successfully once or twice, the relationship has every incentive to move offline. In construction procurement specifically, buyer-supplier pairs tend to be long-duration and relatively fixed once they work, which means the platform that introduced them is, from that point forward, collecting rent on a relationship it no longer meaningfully mediates.
Multi-homing compounds this. If a supplier faces zero friction to list on your platform, it faces zero friction to list on three others, and so does every competitor's supply: the barrier to replicating your supply-side density is therefore close to zero for anyone with capital. You have no contractual presence in the ongoing relationship, so you have no operational lever to force volume to keep routing through you as it scales. Buyers, meanwhile, do not care about your platform: they care about price, quality, and lead time on the specific order in front of them, and they will use whichever channel surfaces the best option for that order. Liquidity on both sides (demand and supply) sounds like a moat, but the incentive of both sides is to be present everywhere, which is the opposite of lock-in. And adding AI to the matching does not change any of this: sure, it makes the discovery event slicker, but it does nothing about the fact that the discovery event is the only thing you own.
This is why, in my view, the real version of the outcome thesis requires owning the supply rather than merely connecting it. You have to be the supplier of record: the party that actually commits to the delivery date, carries the quality obligation, manages the logistics, and absorbs the variability when something goes wrong. Concretely, that usually means building or controlling capacity (buying it, contracting it, standardizing and operating it with technology) and monetizing on the outcome (or usage) rather than on a transaction fee. The defensibility then comes from a completely different place than a marketplace's: from owning delivery, from a track record and trust that compound with every job completed, and from capturing a widening share of the value chain over time. A managed network that orchestrates supply to guarantee an outcome is a fundamentally different (and far more defensible) animal than a matchmaker that introduces two parties and hopes they keep coming back.
Clearly, delivering physical outcomes is exponentially more complex than delivering digital efficiency. You are committing to managing supply chains, coordinating with trades, and handling real-world variability. But that complexity is the point: it is precisely the difficulty of doing this well that keeps it from being commoditized.
Conclusion

AI procurement agents in construction are genuinely useful tools that solve real problems.
But useful and defensible are not the same thing: the technology layer is commoditizing rapidly, the data moats are weaker than advertised, the switching costs are real but moderate. The systems of record that agents depend on are durable and their owners are aggressively shipping their own agentic capabilities. And most fundamentally, these agents address the administrative layer of a problem set whose hardest dimensions (physical supply constraints, relationship dependencies, price volatility, engineered-to-order complexity) remain resistant to AI automation.
In my opinion, the AI agent, by itself, is a feature. Building a company on it alone is akin to building on sand. The question is not whether AI will transform construction procurement, because i think it will, at least to a degree. The question is whether the value accrues to specialist startups, incumbent platforms, or the distributors and contractors themselves. My bet is that the answer is mostly the latter two, with a handful of outcome-oriented companies capturing the rest.
As always, I'd love to be proven wrong, so if you have a different view, or you're building in the space and think I've got it backwards, reach out: I'm always up for the conversation.
More appetite for this type of content?
Subscribe to my newsletter for more "real-world" startups and industry insights - I post monthly!