
.png)

Scan-to-BIM: several founders have attempted to crack this problem and raised venture capital in the process. Yet, no one has fully solved it, though significant advances have been made along the way.
I don't claim to be an expert here - far from it. But I happen to have spent some time diving into the space (and reading tens of academic papers in the process), so I thought I'd share what I've learned and my perspective.
Consider the following as my attempt to make sense of where we are, why full automation remains so elusive, and where the real opportunities might lie for whoever finally cracks the nut (and how it can be done).
Scan-to-BIM: what and why
.png)
For decades, the AEC industry operated in a world of 2D drawings and manual measurements. The process was a mess of inaccuracies and inefficiencies that anyone who's worked on a renovation project knows all too well. When Building Information Modeling (BIM) finally arrived, it felt revolutionary: these data-rich 3D models transformed how we approached new construction. But here's the catch: BIM was primarily designed for projects starting from scratch, so the vast inventory of existing buildings around the world remained stuck in documentation purgatory.
This is where Scan-to-BIM comes into the picture, bridging that critical gap by creating high-fidelity digital representations of existing structures, capturing the precise as-built conditions of buildings. And this matters enormously because renovation, retrofitting, and facility management of existing buildings represent a massive chunk of global construction activity, not some niche market. The importance of this technology really crystallized when governments started mandating BIM adoption: these mandates created a cascading effect, forcing everyone from contractors to consultants to adopt standardized digital workflows, overall establishing a regulatory environment where digital transparency and data sharing became table stakes. So, when you're dealing with existing buildings in this new world, accurate as-built models become prerequisites.
So what exactly is Scan-to-BIM?
At its core, it's a workflow that transforms real-world 3D scan data into detailed digital building models. Teams use LiDAR scanners or photogrammetry to capture existing conditions, then convert that data into BIM-ready formats. This eliminates the soul-crushing manual measurement work that traditionally consumed weeks or months of project time, while delivering dramatically more accurate and complete information.
The practical applications are compelling. When you're documenting existing buildings for renovation, laser scans get transformed into accurate as-built BIM models that reflect the actual current state of the facility. This becomes invaluable for design work and clash detection during retrofits: you're working with millimeter-precise reality, not assumptions. For new construction, teams can scan completed buildings and compare them against the design models to identify deviations and create true as-built records: this gives facility managers and owners a reliable foundation for future modifications and maintenance, which is very useful over a building's lifecycle.
What we're seeing with Scan-to-BIM is the construction industry finally closing the loop between physical buildings and their digital twins: it's enabling data-driven renovations, dramatically reducing construction clashes, and supporting proactive facility maintenance in ways that simply weren't possible before.
Yet despite all this potential, the process remains surprisingly manual and labor-intensive, still far from the plug-and-play automation you'd expect from technology this important in modern construction. One step at a time, though - we'll get there.
Let's first start by better understanding what the Scan-to-BIM process entails.
Capturing reality: the point cloud

The Scan-to-BIM process starts with capturing the physical world through 3D data collection, either via LiDAR scanning or through photogrammetry: LiDAR scanners emit laser beams that sweep systematically across surfaces, measuring distances and angles with remarkable precision, while photogrammetry captures overlapping photographs from multiple angles and uses specialized software to reconstruct 3D geometry through triangulation. What you get from both methods is a dense collection of data points (called point cloud, often containing hundreds of millions of points) that represents the three-dimensional geometry of whatever you've captured with high fidelity.
Mind you: you can't just set up a scanner in one spot and call it a day. Complex buildings have corners, columns, and countless obstructions that create blind spots. So teams conduct multiple scans from different vantage points, ensuring comprehensive coverage and minimizing those occlusions (areas the scanner simply can't see from a single position). The quality of your final point cloud depends on several factors: scanner resolution, environmental conditions like lighting and surface reflectivity, and how thoughtfully you planned your scanning positions. Get this wrong, and you're looking at gaps in your data that will haunt you throughout the project.
The sheer scale of these datasets presents its own challenges: depending on the size of the scanned area, point clouds routinely get into hundreds of gigabytes. Leaving that aside, once you've captured potentially billions of points representing your building, the real work begins. The raw point cloud is essentially useless until it's (pre)processed, and this happens in two critical stages.
First comes alignment. Each scan you took represents a specific segment of the environment from one particular perspective. These individual scans need to be accurately merged into a single, cohesive point cloud. The alignment process uses sophisticated algorithms to detect where scans overlap and calculate the precise transformations needed to align them. This isn't trivial: we're talking about achieving millimeter-to-centimeter accuracy, because even minor misalignments can cascade into significant errors in your final model. Modern software can handle this remarkably well, but only if you give it enough overlap between scans and follow a solid scanning strategy.
The second stage involves cleaning up the mess. Raw point clouds are... raw: they contain all sorts of extraneous data from transient objects like people walking through your scan, reflective surfaces causing erroneous readings, or just general environmental interference. The goal is to obtain a crisp, clean point cloud showing only the static features you actually care about, such as building surfaces, structural elements, etc., without artifacts from passersby.
The next phase (segmentation and feature extraction) is where intelligence gets added to the data. This involves identifying and grouping points that belong to distinct building elements: walls, floors, pipes, windows, doors, structural columns, and so on. Traditionally, this has been an incredibly manual and time-consuming process, with technicians essentially tracing over the point cloud to identify each element. It's precisely this step that's becoming the first target for AI-driven automation, so let's dive into it right away.
From points to semantics: segmentation

With a clean, registered point cloud in hand, you've really only solved the easy part. The next phase (segmenting the point cloud, and later converting it into useful BIM models) is where things get genuinely complex: this is the stage where millions of XYZ coordinates need to become walls, floors, columns, and mechanical systems. To get there, you need to first segment/classify the points in the point cloud by labelling regions of points as specific building elements: without proper classification, you can't create the parametric objects that make BIM actually useful.
The core challenge is this: point clouds describe surface geometry in excruciating detail, but they contain zero information about what those surfaces actually represent. They're just coordinates in space, maybe with some color data if you're lucky. The magic (and the difficulty) lies in transforming this raw geometric data into intelligent, parametric BIM objects that know what they are and how they relate to each other.
The automation of this process breaks down into two fundamental tasks that sound simple but are very complex in practice, and are the reason why we're still struggling to reach full automation. Why?
First, you need to understand the semantics of the 3D scans. This means recognizing which points represent walls, which are slabs, which are columns, and so on. It's incredibly difficult to manually craft rules for recognizing different architectural structures across diverse building styles and flexible designs: a wall in a modern office building looks nothing like a wall in a Victorian-era structure, yet somehow your system needs to recognize both as walls.
Second, you need a topologically consistent and parametric reconstruction of geometry. This involves estimating the shapes, locations, orientations, and dimensions of (wall) solids without conflicts, despite inevitable noise, outliers, and non-uniform sampling in your point cloud. Real-world scans are messy - surfaces that should be perfectly planar have bumps, edges that should be sharp are fuzzy, and occlusions mean you're often working with incomplete data. More on this later.
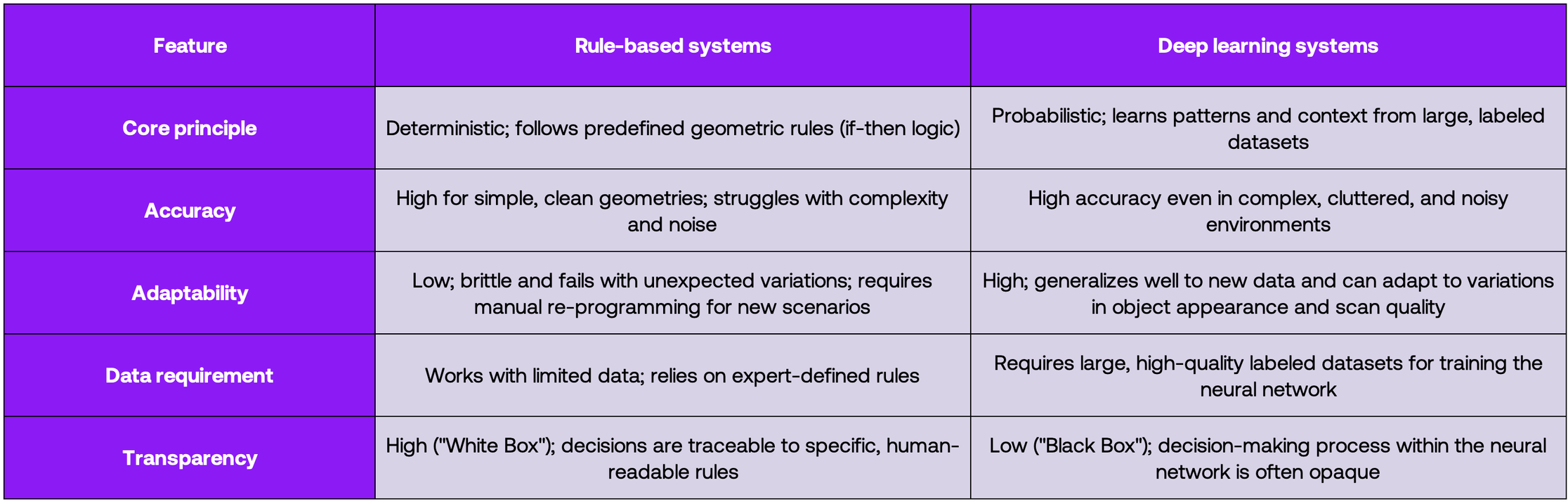
The approaches to semantic segmentation generally fall into two camps: rule-based and learning-based methods.
The early methods for point cloud segmentation, many still common today, rely on explicit rules and geometric algorithms carefully crafted by experts. These approaches don't learn from data but rather apply deterministic criteria to cluster and classify points based on geometric features. The logic is straightforward: if you can define what makes a wall a wall (it's vertical, planar, has certain dimensions, etc.), then you can write rules to find walls in point clouds. Rule-based inferencing encodes expert knowledge as IF-THEN statements that identify objects based on unique combinations of features. Find a large vertical plane? That's probably a wall. Horizontal plane at ground level? Floor. And so on.
The advantages are real. You don't need training data, which matters because obtaining labeled point clouds is incredibly laborious. They're also interpretable, which helps when debugging or explaining results.
However, these approaches often require numerous input parameters (e.g. angle thresholds, distance tolerances, cluster sizes) and those parameters need constant tuning. Generalization is by and large difficult: what works for one building might fail on another because the fundamental heuristics no longer apply. Rule-based methods work well in constrained cases (clean, structured scenes with predictable geometry) but they struggle with the inherent messiness of real-world scan data: noise, occlusions, complex non-standard shapes, and the endless variety of architectural styles.
Learning-based methods aim to overcome the above shortcomings.
Instead of searching for simple geometric shapes, neural networks trained on vast datasets learn to classify each individual point with semantic labels (e.g. wall, floor, ceiling, door, pipe, etc). The shift is profound: we've moved from purely geometric analysis to semantic interpretation. Early landmark works like PointNet and PointNet++ demonstrated something remarkable: neural networks could directly consume raw point coordinates and output class labels for each point. Since then, the field has exploded with architectures like RandLA-Net and Kernel Point Convolution, each pushing the boundaries of what's possible. These data-driven, probabilistic approaches are far more resilient to noise and variation, accurately interpreting complex scenes where rule-based systems would simply give up.
The paradigm shift is this: traditional automation tries to solve a geometric problem - finding planes, cylinders, primitive shapes in disorganized points. But the built world isn't composed of perfect geometric forms. Deep learning solves a more powerful, abstract problem: semantic interpretation. The AI doesn't just identify a large, flat, vertical collection of points; it learns to interpret that collection as a wall. It doesn't see a long, thin, cylindrical shape; it recognizes it as a pipe. This leap from geometry to semantics is the crucial breakthrough that allows systems to imbue raw, unstructured data with meaning - the necessary prerequisite for generating intelligent BIM elements rather than dumb geometric solids.
These methods excel because they understand context in ways that rule-based systems never could. Yet, the complexity and variety of the built environment continue to humble our best algorithms. And more importantly,the Scan-to-BIM workflow is not even done yet: there's one more step left.
The last step: modelling
As we've seen, converting point clouds into BIM requires both semantic understanding (what is what in the cloud) and geometric reconstruction (precisely modeling each part). Therefore, once you've successfully segmented your point cloud and identified what's what, you face the next hurdle: creating actual BIM objects from those classified point clusters. This is where the rubber meets the road, because BIM elements aren't just three-dimensional shapes floating in space. They're intelligent, parametric objects that carry both geometric and non-geometric information. A wall in BIM isn't simply a vertical surface; it has defined parameters like height, thickness, material composition, etc. It knows where it starts and ends, how it connects to adjacent walls, and what happens to attached elements like windows or doors when you move it.
This parametric nature is what makes BIM powerful, but it's also what makes automated reconstruction so difficult. The modeling process typically involves fitting geometric primitives to your classified point clusters: planes for walls, cylinders for pipes, rectangular prisms for columns. But here's where it gets tricky. Your scanned wall probably has minor bulges, surface irregularities, and measurement noise. The BIM wall you create needs to be perfectly planar and vertical, with clean edges and precise dimensions. You're essentially creating an idealized representation of a messy reality, and that idealization requires judgment calls that could be are hard to automate.
Besides, beyond individual objects, BIM models encode relationships and hierarchies that point clouds simply don't contain. Each element belongs to a category and follows parametric rules about how it behaves in the model. A wall knows it should span from floor to ceiling and automatically join with perpendicular walls. Windows understand they need to be hosted within walls. If you move a wall, the doors and windows embedded in it move along with it. Capturing these relationships automatically is remarkably challenging. If your AI misclassifies a structural column as a wall, that BIM object will behave incorrectly throughout the entire model, causing cascading issues.
There's also the metadata problem. BIM elements store information that's physically impossible to derive from laser scans alone: material specifications, manufacturer details, installation dates, maintenance schedules. Your point cloud might show you a pipe, but it can't tell you whether it's carrying potable water or sewage, what material it's made from, or when it was installed, etc. - this gap between what scans can capture and what BIM demands is another reason why human involvement remains so critical (it also depends on the required LOD).
Therefore, the traditional workflow for creating these BIM models from point clouds has been mostly manual. A skilled technician imports the point cloud into software like Revit and essentially traces over it, reconstructing each building element one by one. They'll sketch wall lines where scan points align in plan view, extrude pipes along detected centerlines, and manually place doors and windows where the geometry suggests openings exist. This approach is extraordinarily time-consuming and expensive, often representing the single largest cost and time-consuming activity in the entire Scan-to-BIM workflow. For complex projects, particularly heritage buildings with irregular geometry and non-standard construction, this manual work can take weeks.
The industry has developed semi-automated tools that sit somewhere between fully manual and fully automatic. These software packages offer assistive algorithms that detect planar regions for walls, identify tubular point clusters for pipes, or suggest where edges and corners might be. The human operator then validates these suggestions, adjusting them where the algorithm got it wrong or filling in gaps the software couldn't handle. This speeds things up compared to pure manual tracing, but it still demands significant human judgment and correction. The software might correctly identify 70% of the walls but completely miss the curved ones, or it might detect all the pipes but misclassify their diameters.
On the cutting edge, researchers and a handful of commercial tools are attempting fully automated extraction: feeding point clouds into algorithms that output BIM elements with minimal or zero human input. These systems use machine learning to classify points and then reconstruct simplified geometry for each category. The promise is compelling, but the reality remains limited. Fully automated approaches tend to work only in relatively simple, structured environments. No off-the-shelf solution today can reliably take an arbitrary building scan and output a complete, production-ready BIM model without significant human oversight and correction. The technology is advancing rapidly, with AI pushing the boundaries year by year, but we're not there yet. The gap between research demonstrations and tools that work reliably in production remains substantial.
Why automation remains elusive
.png)
Despite all the technological progress, fully automating the Scan-to-BIM pipeline remains stubbornly difficult. We're still far from fully automating Scan-to-BIM, and it's worth spending time understanding why we are so far from it. Brace yourself, because this is going to be long!
As we've seen, deep learning/AI models show promise in segmentation, but are not without shortcomings themselves. The most immediate barrier to full automation is the quality and quantity of training data: AI models are data-hungry beasts requiring diverse, annotated datasets to learn from. However, a 2024 analysis revealed that 90% of AI research in scan-to-BIM relies on synthetic or limited real-world data, which severely reduces practical applicability. Unfortunately, the process of creating training data is mind-numbingly labor-intensive: it requires manually annotating point clouds, meaning labeling individual segments and elements point by point, which is far more tedious than labeling 2D images. This creates a massive bottleneck in developing more accurate models.
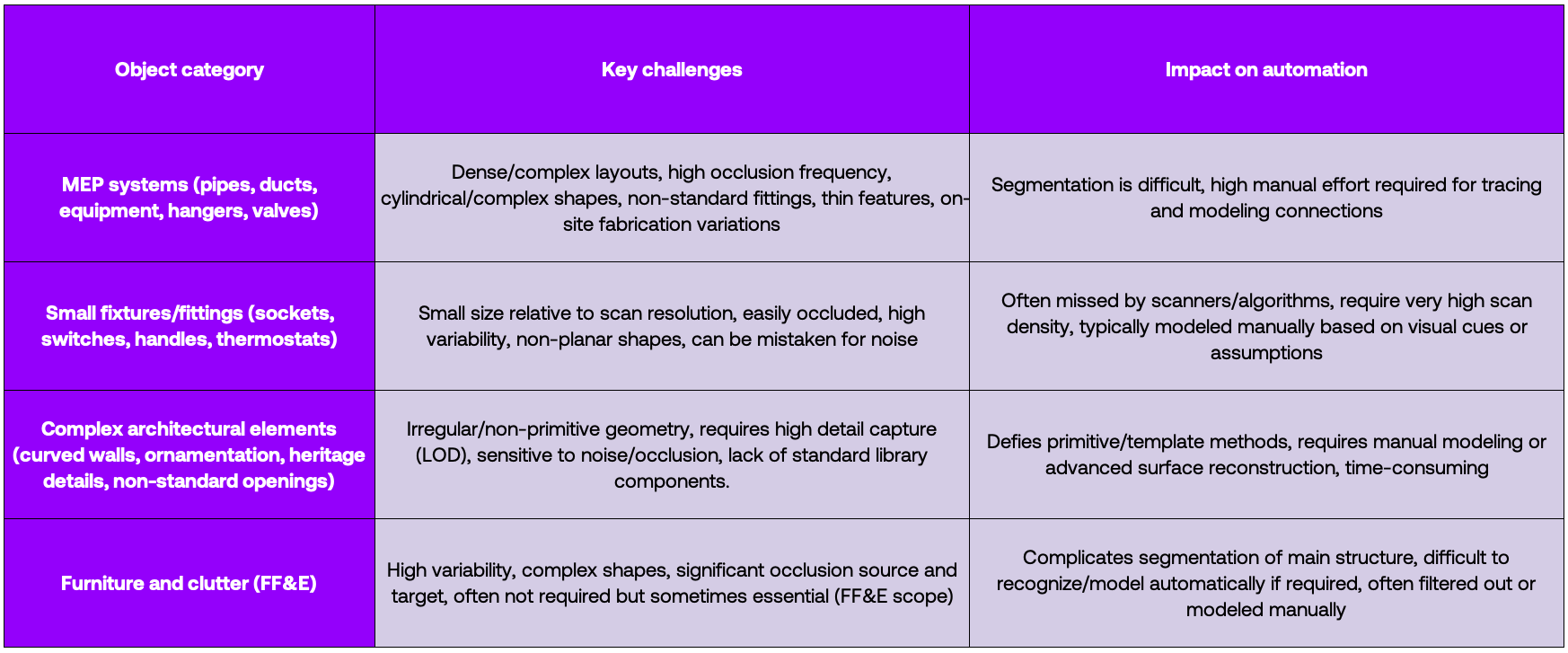
Second, the real killer is what we might call the "long tail" of building elements. Most research and applications to date have focused on structural components like floors, ceilings, columns, and walls, maybe throwing in doors and windows. These elements, while not easy to detect, are at least often planar or regularly shaped. But buildings are filled with countless other (non-structural) objects that defeat automation. The reasons these objects are hard to automate stem from a combination of factors: 1. Geometric complexity; 2. Scale (very small objects relative to the overall scan resolution, or very thin); and 3. Variability and lack of standardization (high variation in form, size, and style makes template matching or other recognition techniques ineffective; we'll discuss this below).
Additionally, the challenge of modeling incomplete point clouds from obstructed objects remains significant: occlusions, scan shadows, and varying point densities all contribute to the difficulty of accurately interpreting raw point cloud data. For example, a pipe behind another may have a missing segment of points, which an algorithm must interpolate or risk leaving a gap; or, indoor objects like furniture occlude walls and floors, causing missing structural elements in the scan. Missing data is a key limitation in Scan-to-BIM algorithms: for a parametric model, guessing can be dangerous (could introduce large errors or non-manifold geometry), while leaving it incomplete breaks the BIM's usefulness. If half of a beam is occluded by a ceiling, an automated approach might only model the visible half, unless it's clever enough to infer symmetry or continuity.
That said, even with perfect segmentation (every point labeled correctly), we still need to create BIM objects that are geometrically and topologically consistent: converting segmented points into parametric BIM objects requires not just identification but also precise geometric understanding and adherence to building standards and modeling conventions. Parametric BIM elements (a wall object in Revit or IFC) have regular geometry and defined parameters (width, height, thickness), but real as-built elements deviate from ideal shapes and perfect geometry, therefore an automated system must decide how to fit an idealized parametric form to the scattered points.
This brings us to the core challenge of geometric reconstruction. In this regard, one approach worth understanding is template matching, which treats modeling as an object recognition problem: match each segmented cluster of points to a known object template. This method is commonly used for repetitive or standard components, like matching a scanned pipe run to a parametric pipe segment from a catalog, or replacing a scan of a chair with a similar chair from a library. When it works, this yields true parametric objects directly. However, its effectiveness depends entirely on the library breadth and fidelity. If the exact object isn't available, the nearest template introduces error: small alignment or sizing differences can accumulate, and the result might not exactly fit the point cloud, causing elements to not line up. Research has observed that the preferred approach of retrieving the best fitting template for each object often leads to noticeable geometric inaccuracies. Furthermore, creating and maintaining an exhaustive library of every possible object, especially for unique or older items, is impractical. Template matching also requires a reliable identification of the object type first, which can be error-prone. While template matching is part of some solutions, it is usually combined with manual adjustment: pure library-matching automation tends to be brittle outside of constrained scenarios.
Continuing, the modeling challenges become clearer when we separate elements into two categories: structured and unstructured.
Structured architectural components like walls, floors, ceilings, and columns often have idealized geometry that suggests they should be easier to model, yet translating even these into parametric BIM objects from scan data poses numerous challenges. Take wall reconstruction as an example: detecting wall planes is feasible with plane detection algorithms, but ensuring complete, connected walls with correct boundaries is hard. Walls meet at corners and have door and window openings: an algorithm must infer where one wall plane ends and another begins at a corner, requiring a topological understanding of room layout. Additionally, in BIM, elements like doors and windows are typically hosted by walls, meaning a door is inserted into a wall and automatically creates an opening. From a point cloud, however, a door will likely be a separate labeled cluster, and the wall cluster will simply have missing points in that region. Automating the integration of these is non-trivial. The system must deduce that a door-sized void in a wall's geometry corresponds to a door object, and then create a wall with an opening and place a door component in that opening with the correct dimensions. This involves precise geometric detection of the void's boundaries and aligning a parametric door model to it. Any misalignment and the door won't fit or will clash.
Floors and ceilings present similar issues. These horizontal slabs can be detected as dominant planes, but occlusions from furniture on floors or ceiling clutter like ducts often cause holes in the data. Automated modeling must fill gaps to create continuous slabs. Identifying floor slab boundaries requires recognizing wall intersections, and errors can result in fragmented floor surfaces or slight height differences that should be unified. Structural frames like beams and columns are often standardized shapes with rectangular or round cross-sections, and algorithms exist to fit these primitives. However, heavy occlusion in ceiling areas or overlapping scans can cause misses. Deciding if a cluster of points is one continuous beam or several elements aligned, like a steel beam versus a pipe running along it, may need context.
Many structured elements have multiple faces as well. A wall has two faces with thickness, a slab has a top and bottom. A segmented point cluster might contain points from both faces of a wall if scanned from both sides. The modeling algorithm must recognize these are two parallel planes of one wall and determine the thickness. Inferring thickness from noisy data can be error-prone, especially if one side wasn't scanned due to occlusion or if materials cause varying offsets. Without manual hints, automation might produce walls of incorrect thickness or double-count the two faces as separate thin walls.
Unstructured elements like mechanical, electrical, and plumbing components and furniture add another level of complexity. Unlike walls or beams, which follow relatively standard profiles, these objects are often irregular in shape or highly varied in form, making parametric modeling extremely challenging. A point cluster labeled "chair" or "HVAC unit" might correspond to any number of shapes and sizes, and parametric object libraries for such items are not standardized. For example, current (semi)automated methods often simply ignore or roughly represent furniture because of this difficulty: automatically recognizing a piece of furniture and retrieving or generating a matching parametric model with editable dimensions is an unsolved problem in general. At best, deep learning can classify certain furniture types and perhaps approximate their size, but turning that into a proper BIM family placement still often requires a human or a predefined library of objects. For unique or ornate pieces, there may simply be no parametric archetype available.
Many MEP components have freeform shapes as well. Ductwork with custom curved transitions, pipe networks with various fittings, or equipment with organic forms do not reduce to simple shapes easily. Fitting standard primitives like cylinders or boxes can capture some parts, like pipes as cylinders and ducts as rectangular prisms, but complex parts like valve handles, pump housings, or curved duct elbows do not fit these primitives. This leads to partial modeling: an automated tool might detect straight pipe runs well but fail to model the junctions or valves, leaving gaps that require manual patching. Even when primitives can be fit, reconstructing a coherent system requires determining which pieces connect to which, like an elbow connecting two pipe segments into one continuous pipe run. Simply being spatially adjacent isn't always enough, as there could be a tiny gap or an occluded section. Moreover, BIM expects logical system groupings: all ducts connected forming an HVAC system, all pipes forming a hot water system - this semantic grouping is beyond pure geometry, and if the scan doesn't clearly show a connection, the algorithm will likely miss it.
Two broad strategies exist for unstructured geometry modeling: bottom-up fitting, where you extract geometric features from the points and try to assemble an object, or top-down recognition, where you match the point cluster to a known object model. Bottom-up methods are sensitive to data quality, and a few wrong edges or surfaces extracted can cause the assembly to fail. Top-down recognition can fill in missing parts by leveraging prior knowledge, but it requires a library or trained model for each object type. In the industry, there is no comprehensive library for every possible furniture piece or custom MEP component. Thus, automation often falls back to generic representations like bounding boxes or simplified shapes when it cannot precisely model the item, which raises issues with BIM standards compliance: the lack of a parametric standard or canonical form for many such objects means each solution creates its own approximation, reducing interoperability. There's also a trade-off to consider: modeling numerous small unstructured items like chairs, light fixtures, and pipes in detail can explode the BIM's complexity. Even if automation could reconstruct them as meshes or detailed parametric objects, the resulting model might be extremely heavy and unwieldy. This goes against the ideal of a complete as-built BIM.
Ultimately, beyond just getting the geometry right, semantic correctness and parametric fidelity are crucial in a BIM. As anticipated above, a major bottleneck is the lack of a universal parametric template for many objects. BIM software typically uses families or object classes with defined parameters like length, width, and profile shape. However, automatically generating or selecting an appropriate family for each scanned object is difficult: for standard elements like planar walls or round columns, one can use generic families and populate dimensions, but what about a custom-profile beam or an ornate stair railing captured in the scan? There may be no existing parametric family. This lack of parametric standards for arbitrary shapes means automation hits a wall when an object doesn't fit the predefined library. Additionally, an accurate BIM is not just geometry but also carries attributes like material, fire rating, and identity data, along with relationships between elements - automating the assignment of such attributes is largely beyond the capability of geometry-based algorithms, and a point cloud won't tell you a wall's material or a pipe's system type. This means current automation might produce a skeleton BIM that still needs an expert to enrich with non-geometric information.
All of this explains why Scan-to-BIM remains stubbornly manual (or semi-automatic for specific workflows/elements at best) despite years of effort and investment (even from VCs). The question then becomes: if the problem is this multifaceted, what would it actually take to solve it? Before we bring this article home, let me share my perspective on this question.
Getting to full automation: some thoughts (and a thesis)

Now, we've seen what the scan-to-BIM workflow looks like. We've seen what the bottlenecks are and what makes automating the entire workflow extremely difficult. Let me now share how I think the problem could be solved.
It basically boils down to two approaches.
The first approach is to "pick your battles" in domains where automation is more attainable. Instead of trying to handle every building type as a "generalist" solution, one strategy is to focus on a single domain and optimize heavily for it, effectively turning the general Scan-to-BIM problem into a narrower, more tractable one. For example, linear infrastructure scanning (e.g. railways, roads, tunnels) represents a domain where conditions are significantly more favorable for automation, because the geometry is often simpler (long linear or gently curved stretches, mostly open space rather than cluttered rooms, etc.), the object types are fewer and more standardized (e.g. railway tracks, sleepers, signals, and poles all have known dimensions and shapes defined by industry standards), and data capture becomes easier because a rail corridor has fewer occlusions (e.g. no furniture or partitions in the way). In turn, this simplicity and standardization make template creation faster and enable high re-utilization of BIM objects, and make modelling more automatable.

Therefore, in these constrained environments, it becomes plausible to achieve much higher automation rates through a hybrid approach that combines deep learning segmentation with BIM libraries for model reconstruction. Since the variability in BIM objects is reduced, predefined templates eliminate redundant modeling efforts for recurring element types. One could credibly claim automation rates of 80% or higher - but only within these constrained environments.
Clearly, the flip side of domain-specific solutions is their limited scope and transferability: a system built and trained for railways will perform very poorly if thrown at an office building scan, and vice versa - each new asset class is almost a new problem requiring new training data, new templates, or new rules. Moreover, from a market perspective, focusing on one domain can be smart for gaining traction and solving a particular customer's pain really well, but it means the overall impact is narrow and your addressable market is smaller. Lastly, in my view from a VC-case perspective, this approach is not inherently defensible: you're solving a problem significantly less complex, and competitors can replicate domain-specific templates relatively easily.
Given the shortcomings of domain-specific applications, we might want to focus on identifying companies that directly address the fundamental challenges of generalization and complexity inherent in building projects.
Ultimately, I think that the company best positioned for success in this market will be the one that cracks the code for reliably segmenting (e.g. through AI/deep learning) and automating the modelling of "hard-to-model" objects (the long tail, such as MEP, fixtures, complex details, etc.) beyond the basic structural shells, thereby significantly reducing the manual effort required to produce complete BIMs for the broad and complex building market, rather than optimizing for niche applications in more structured environments.
This presents two complications.
First, while AI and deep learning offer the potential to learn complex patterns and classify/segment diverse objects, their application in building Scan-to-BIM still faces significant hurdles. The scarcity of large, diverse, labeled building point cloud datasets limits training effectiveness and model generalization. Models trained on synthetic data or specific environments may not perform well on real-world scans with noise, clutter, and occlusions. This means that improvement in segmentation will likely be the result of more data (from project execution) becoming available to the company solving this problem. This means that improvements in segmentation will likely happen gradually as more real-world project data becomes available, rather than through some "step function". The implication here is also that the company that actually executes Scan-to-BIM projects and delivers outcomes to customers, rather than just selling software tools, will have a structural advantage. Why? Because being in the field, owning the end-to-end workflow, and maintaining direct contact with customers creates both the continuous data flywheel needed to improve AI models and the immediate feedback loops to understand where automation fails and how to fix it. Also, why not operate as an OaaS when the industry purchases services that you can deliver faster, better, and at a higher margin?
Operating as an OaaS company would also grant you control over the scanning phase, which opens up another critical avenue for innovation. While most focus on improving segmentation and modeling algorithms, innovation might come from the data collection workflow itself. I did not spend much time on this topic, but basically, not all hardware allows for the capture of enough detail needed to fully automate the segmentation and modelling of objects, particularly in a building. In fact, to achieve full automation, a novel approach of dual LIDAR + RGB data collection might be needed, as combining LiDAR with RGB data offers a powerful approach for Scan-to-BIM workflows: 1. LIDAR provides accurate structural information and large-scale geometry, while RGB data enhances the detection of small objects through color and texture; 2. Fusing LiDAR point clouds with RGB images can improve segmentation accuracy by leveraging both geometric and color features; and 3. The combination allows for better handling of occlusions, as RGB data can help identify objects even when they are partially hidden. Now, I'm not saying you need to reinvent the hardware here - off-the-shelf LiDAR and RGB cameras can do the job. The innovation is in the collection approach: how you deploy and combine these tools to capture more comprehensive data than standard (single tool) scanning workflows, which in turn unlocks has the potential to unlock better automation.
Second, the hardest task is that of unlocking flexible geometric modeling to accurately model complex, irregular, and parametric geometries directly from point cloud data. The core challenge here is moving beyond pure template-matching approaches toward something more dynamic and "generative". To be clear, template libraries absolutely have their place: for standardized elements like structural components, repetitive objects, etc., matching against a library remains the most efficient solution. Hence, the smart approach is to use templates wherever they work well, which is why domain-specific applications in railways or industrial facilities can achieve high automation rates. However, for the broader building market with its long tail of diverse objects, a "passive" template-only approach fundamentally won't scale (for the reasons highlighted earlier in the article). Therefore, I think that the solution lies in integrating generative modeling or learnable parametric shape representations that can dynamically create new BIM families on the fly: rather than searching for the nearest match in a static library, the system would learn to generate parametric representations directly from the point cloud data, effectively creating custom families for objects it has never seen before (and then storing them for future use/retriaval). I'm not saying this is simple (quite the opposite!!), but this hybrid approach (leveraging templates where appropriate but capable of generative modeling for everything else) is what I think is needed to tackle the full complexity of diverse building environments.
Conclusions
.png)
The evolution of Scan-to-BIM encapsulates the broader digital transformation of the construction industry: it has progressed from niche and manual technique to a mainstream process that is becoming a cornerstone of modern project delivery and asset management.
Yet, as we've seen, the path to full automation is far steeper than most anticipated. The long tail of building elements, the complexity of parametric reconstruction, the scarcity of quality training data, and the need to balance geometric accuracy with semantic correctness all conspire to keep this problem stubbornly unsolved. Most attempts have either retreated to domain-specific niches where the problem is more tractable, or delivered semi-automated tools that still require substantial human intervention. The nut hasn't been cracked yet, but luckily the pieces are starting to come together.
All in all, I believe that the opportunity lies in taking a fundamentally different approach, both technical and in how the product is sold on the market. In fact, the first and simplest change starts with a business model shift: rather than building yet another software tool that customers struggle to use effectively, the winning company will need to deliver outcomes (I talked about Outcome as a Service here, and my colleagues Shub and Patric have also talked and written extensively about it here: 1, 2, 3, 4). This approach creates the data flywheel essential for improving AI models, provides the immediate feedback loops to understand where automation fails, and most importantly, keeps you close to the actual problem you're solving rather than abstracting it away behind a software interface. Obviously, OaaS as a GTM is useless without a product that works 100x times better than anything else on the market. For that, I think that the winner will likely be the one that combines AI for segmentation, generative modeling for flexible parametric reconstruction, and potentially innovative dual LiDAR and RGB capture (and as said, wraps it all in a service model that continuously learns and improves with every project executed).
It's easier said than done, I know. It's a hard problem (perhaps one of the hardest in ConTech?), but the market is large, so cracking it will be handsomely rewarded by those who manage to.
#ScanToBIM #BIM #ConstructionTech #ConTech #AEC #Startups #PointCloud #DigitalTwins #OutcomeAsAService
More appetite for this type of content?
Subscribe to my newsletter for more "real-world" startups and industry insights - I post monthly!
Head to Foundamental's website, and check our "Perspectives" for more videos, podcasts, and articles on anything real-world and AEC.